遵循了DDD中的CQRS<命令和查询职责分离>
背景
调研
设计
系统交互
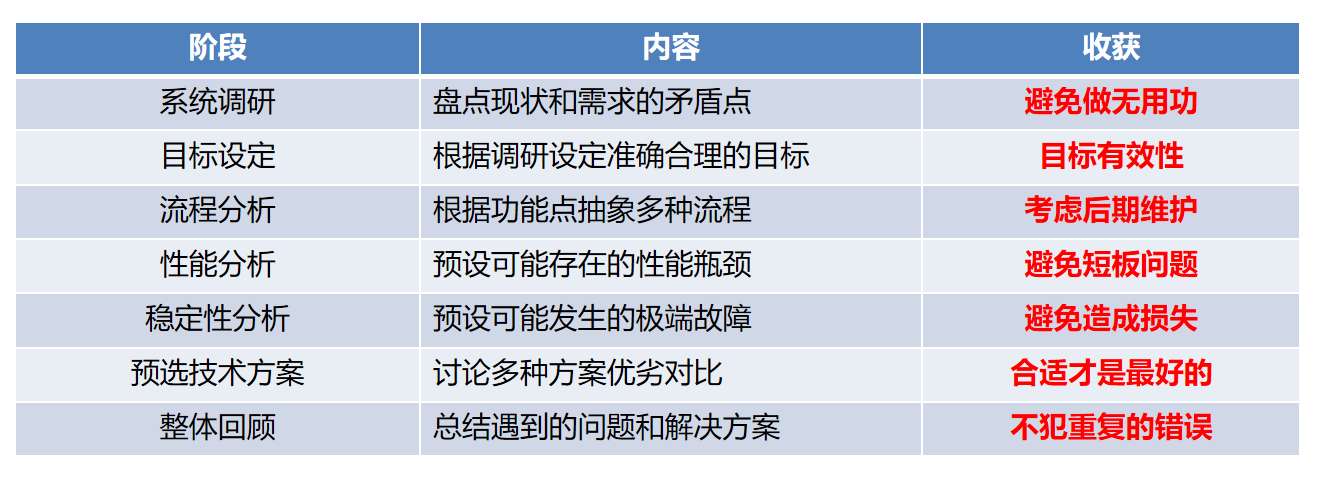
中间是基础数据平台,左边是数据来源,右边是各个业务线
基础数据平台是一个典型的分布式配置系统,包括维护方和使用方,总共有四个系统。
维护方
- 运营端系统,主要负责增删改查,和各个数据来源进行交互
使用方
- 服务端系统,主要负责提供全量数据的查询,将全量数据加载到缓存中,和客户端交互
- 客户端系统,业务线引用的Jar包,主要负责将全量数据按业务逻辑加载到业务线的本地缓存中,给业务线提供调用的方法
- 提供端系统,相当于一个引用了客户端Jar包的业务线应用,主要负责给其它业务线提供服务化接口
运营端系统
运营端的概览
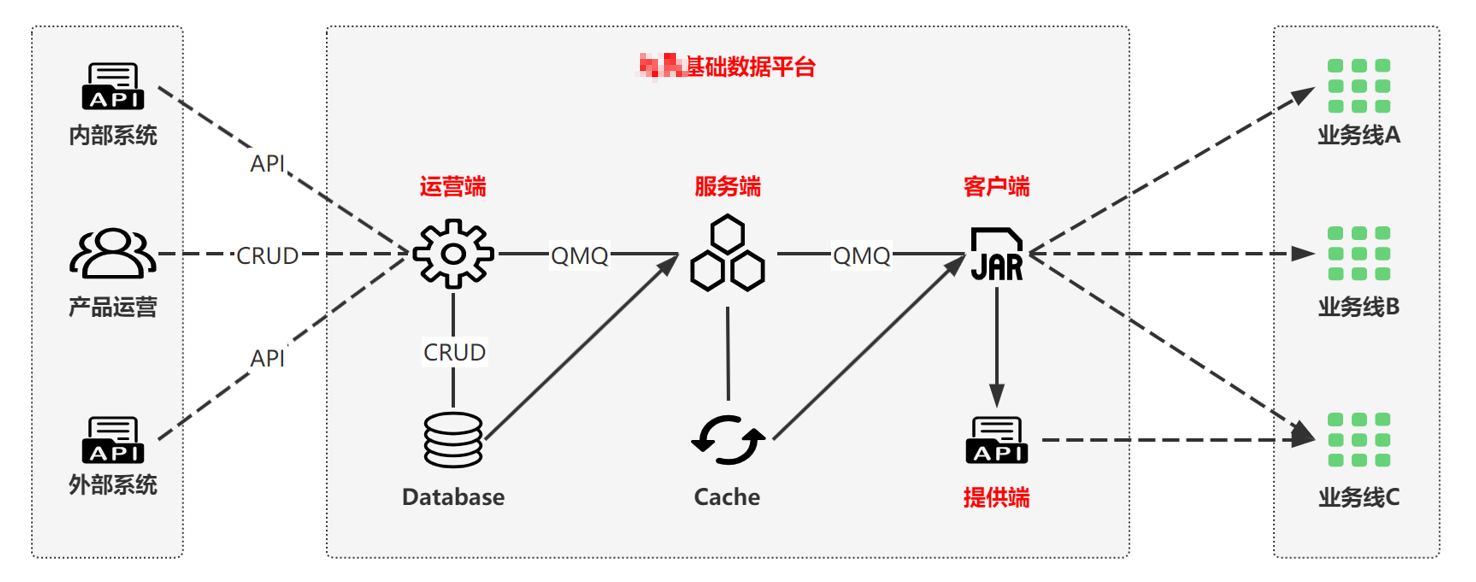
这个系统主要分为数据管理和状态流转两部分
我们把配置数据分成编辑表和发版表,编辑表用于编辑,发版表用于发版和回滚
状态流转就是将每一步操作进行加锁解锁,直到数据发布成功通知服务端
运营端的流程
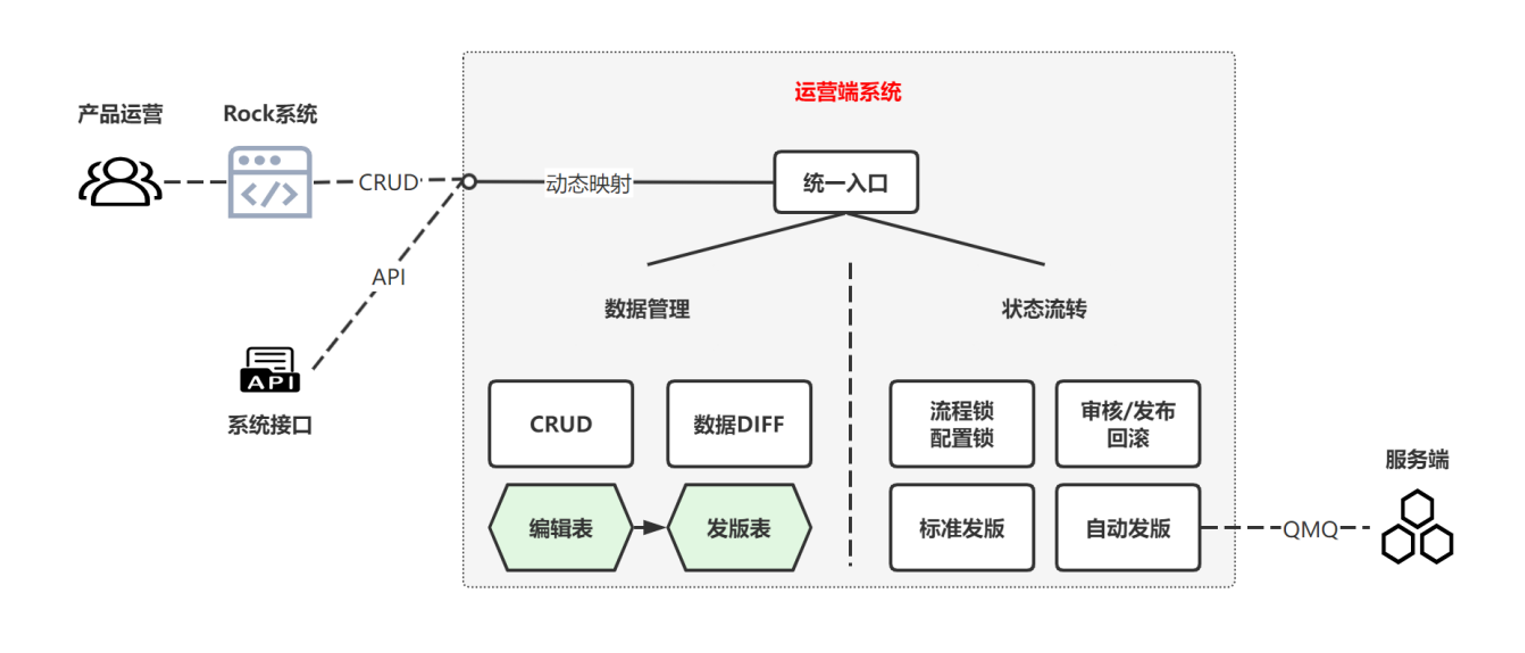
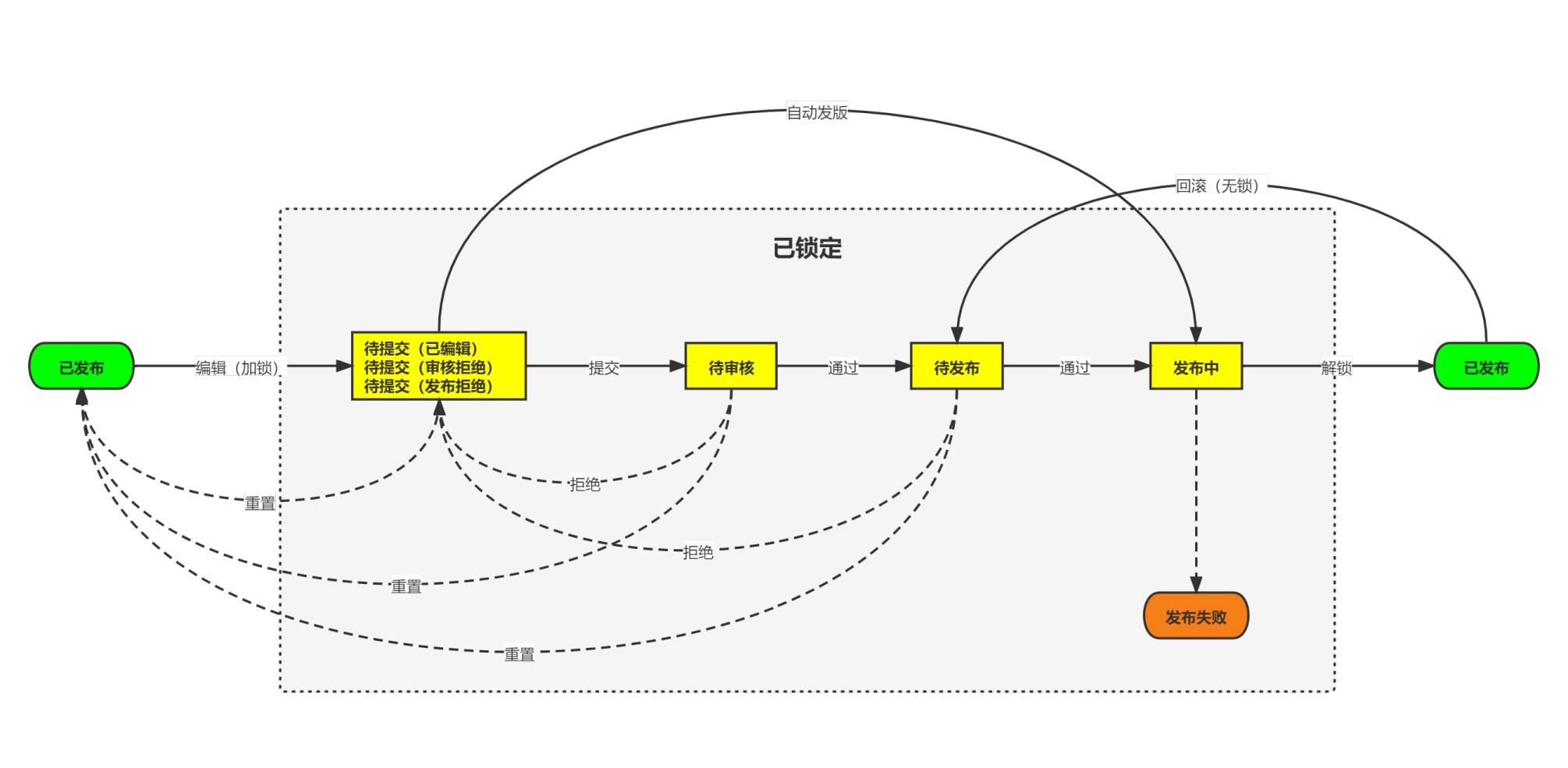
目前运营端总共有6种流程,前三种有状态流转,后三种没有状态流转
第一种是标准流程,像国内舱等就是这样,因为需要人工介入,数据就有状态,流程需要上锁,同时用到了编辑表和发版表
另外我们还有定时任务去拉取外部接口接口的数据,和人工发版的数据进行合并,再次发版就是第三种流程
我们有内部系统接口来实时的增删改,这样数据不需要状态,人工和系统都直接在发版表上操作然后发版
运营端的状态机
运营端的发版方式
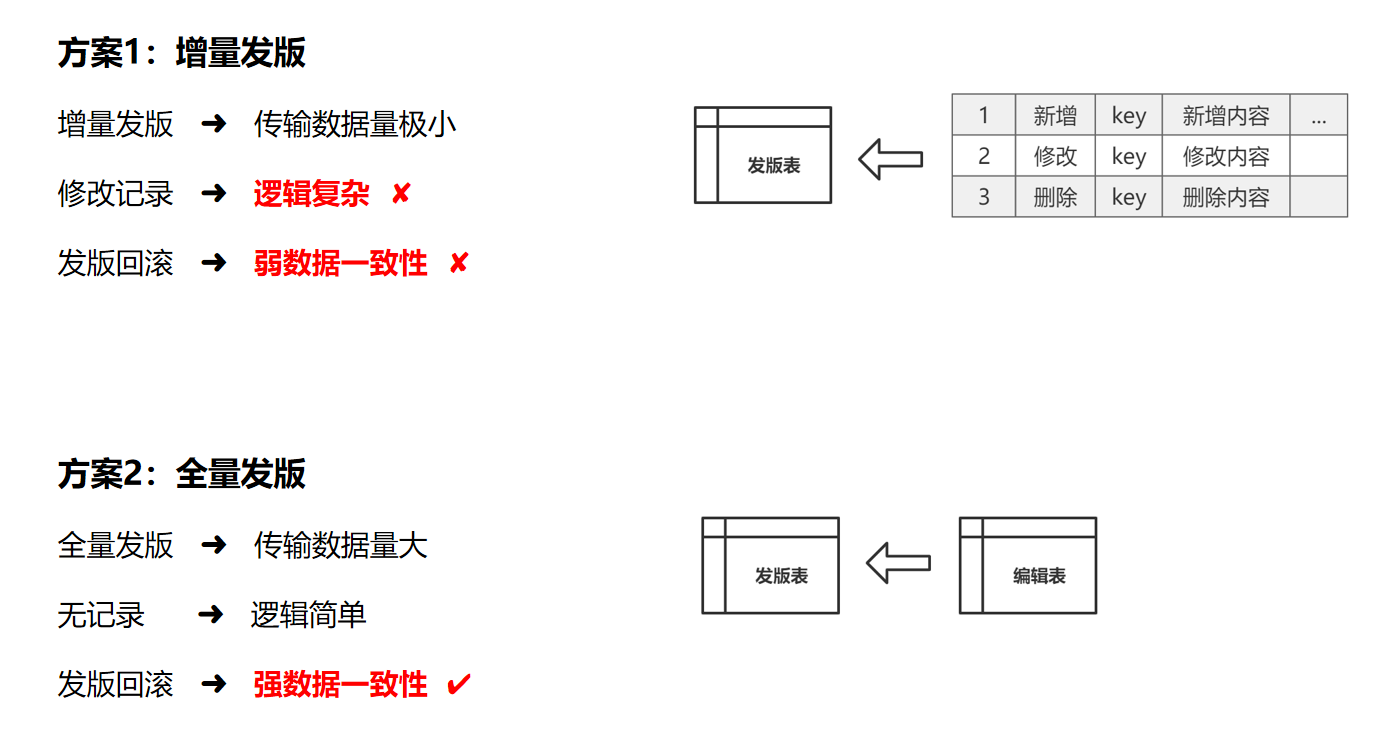
用增量发版,用一张表存储新增的内容,修改的内容,删除的内容
这样,每次的传输数据量都很小,也就不会有太高的性能要求
但增量的话,像版本更新,回滚,逻辑比较复杂,而且比较难保证数据的一致性
采用全量发版,这样虽然每次传输的数据量大,但不需要记录修改的过程,逻辑比较简单,更能保证数据的一致性
运营端的存储方式

用统一的索引表,这样每一个配置类型的表结构表字段都是相同的,有固定的索引,每一个索引配置映射到对应的字段,这样我们就可以复用所有配置类型的DAO层,新接入数据的成本非常低
但是这样需要后期维护一个复杂的索引和字段映射关系,考虑到后期的可维护性
统一所有数据类型的公共字段,每一个配置的表结构和字段不一样,但能复用基本的DAO层,这样虽然新接入数据成本比第一种方案高一点,但是后期可维护性很好,很容易扩展
运营端数据库设计
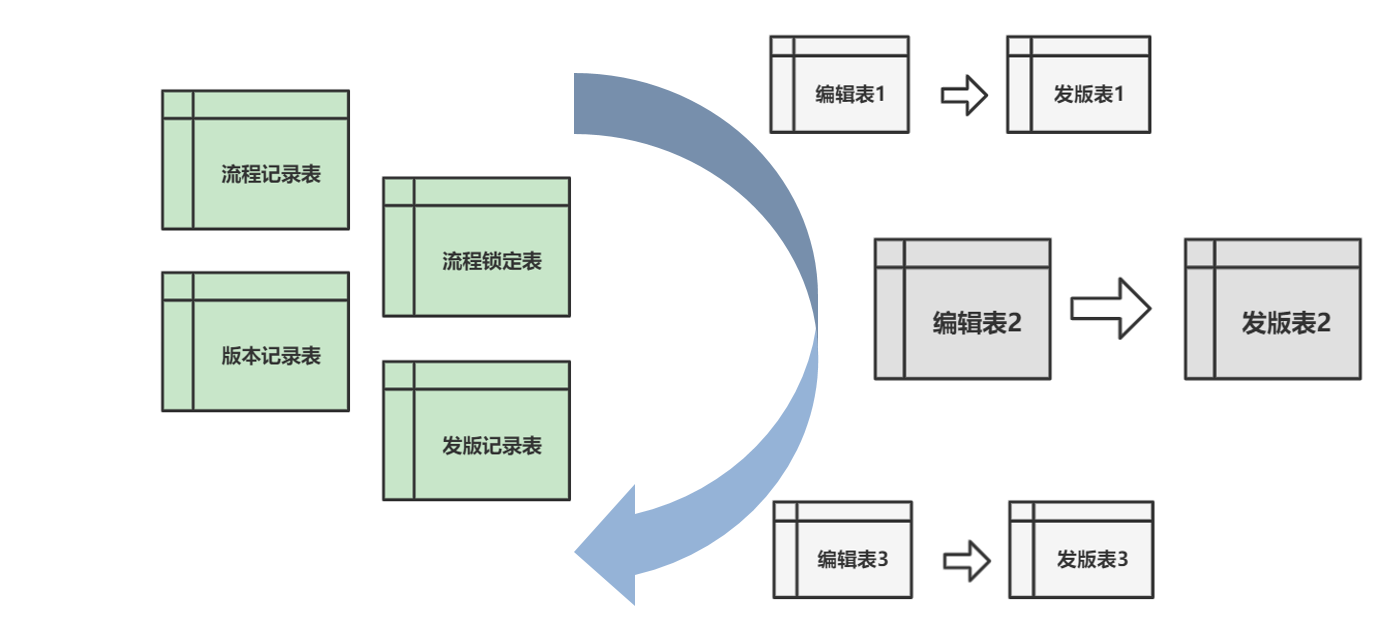
多组配置类型的编辑表和发版表共用一套公共基础表
服务端系统
服务端的概览
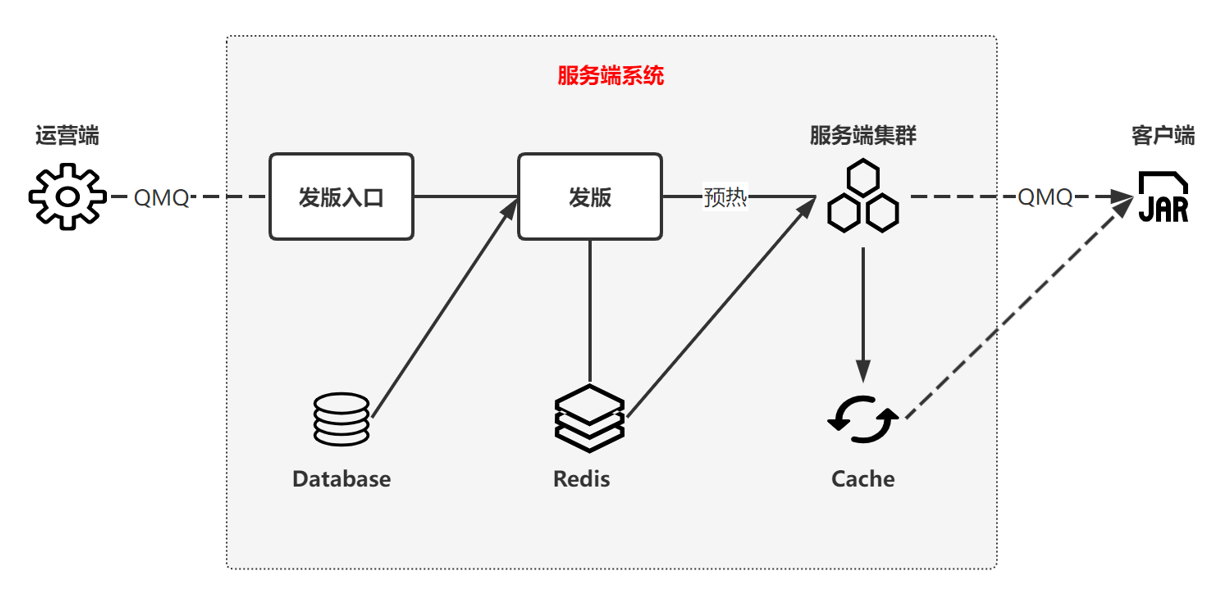
服务端系统,提供全量数据的查询功能
服务端收到运营端的发版消息后,从MySQL数据库里加载到Redis缓存中,再通过预热机制加载到各个服务端机器的本地缓存中,最后再通知客户端版本更新了,来拉取全量数据
服务端的性能场景分析

服务端直接和业务线交互,我们分析了一下性能场景,比如有400多个应用在用我们的地理位置,当我们更新地理位置的时候,需要让所有的应用大概有3000多台机器在10秒左右的样子生效,这是一个性能瓶颈,这样的请求量的瞬间飙升对服务端的性能要求还是比较高的
我们的解决方案有:
首先在发版的时候对服务端集群的所有机器进行预热处理,把全量数据都加载到本地缓存中,等服务端集群准备好了之后,再通知客户端来拉数据
针对不同的业务线,有的配置类型是懒加载的,我们根据前一天业务线的数据使用情况,只加载更新业务线使用过的配置类型,这样来减轻服务端的压力,这是性能场景分析
服务端的稳定性分析

客户端的机器启动的时候,会初始化加载配置类型,这个时候的请求量是初始化配置个数乘以机器个数瞬间的流量会很大,而且业务线是强依赖部分配置类型,比如说地理位置,地理位置初始化失败,就会启动失败
我们的解决方案有:
在客户端对瞬间的大量请求进行秒级别的错峰处理,以此来减轻服务端的压力,避免服务端请求阻塞
每次发版,都将全量数据上传到了OSS,容器启动时,都会从OSS加载历史备份文件,当服务端不可用的时候,容器启动时就用历史备份文件,这样来达到容灾的效果
设想的一个故障场景:
某个应用发布上线后发现问题,马上开始大批量回滚,这时候有叉乘的请求量,导致服务端请求阻塞,但应用又强依赖这些配置,就会导致回滚部分失败
客户端
客户端的概览
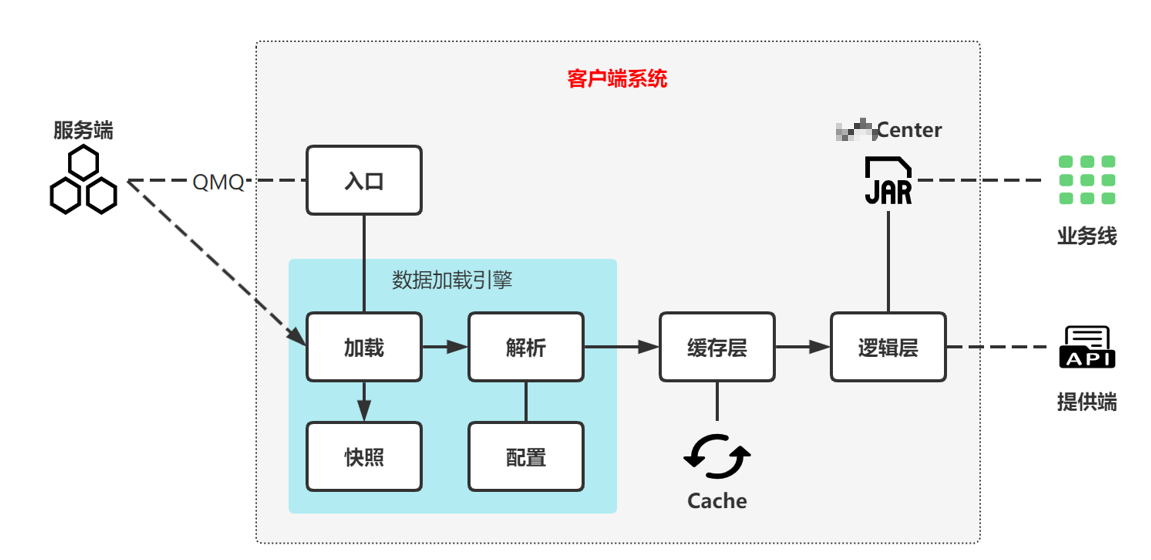
我们的客户端系统,从服务端拉取到全量数据之后,通过我们的数据加载引擎,进行本地备份和数据解析各个配置类型有各自的解析器,将全量数据按业务方想要的方式存储在本地缓存中,再给业务线暴露多个调用方法
客户端的性能优化
提供端
提供端的概览
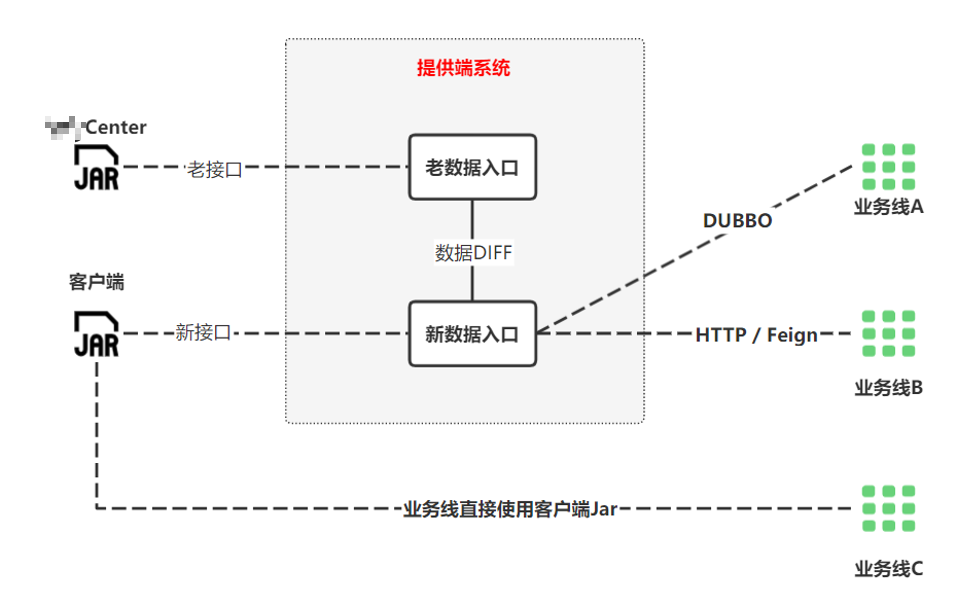
我们的提供端系统,和前面的以空间换时间相反,这个系统我们是以时间换空间我们引入了客户端Jar包,给业务线提供HTTP、DUBBO、Feign服务接口另外,我们在这个提供端系统上进行数据迁移的DIFF测试,新接入数据的性能测试等等
总结